Our New Publication: Advancing Reliable AI for Medical Imaging with the CURVAS Challenge
We are excited to announce the publication of our latest work: the results of the CURVAS Challenge (Calibration and Uncertainty for Multi-Rater Volume Assessment in Multi-Organ Segmentation), presented at MICCAI 2024 last year.
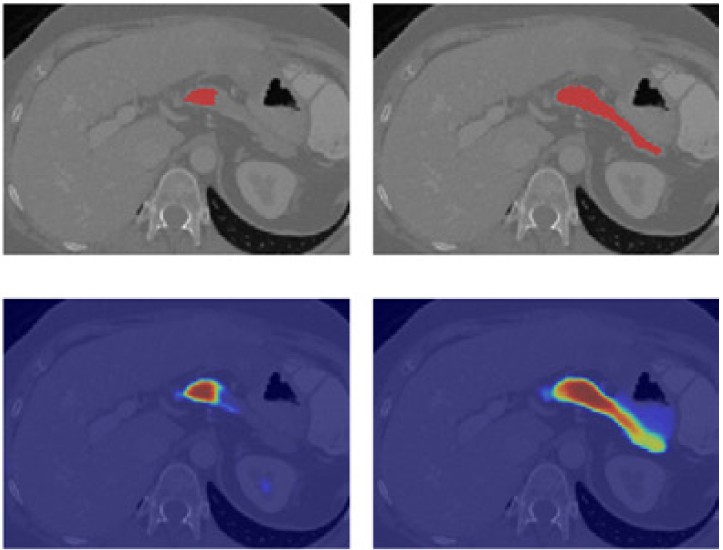
Although medical image segmentation with deep learning (DL) has become a cornerstone of modern radiology, its clinical use still faces critical challenges: variability between expert annotations, limited model calibration, and the need to estimate uncertainty. The CURVAS challenge was designed to address these difficulties by providing a structured benchmark focused on the abdomen, specifically the liver, pancreas and kidneys, using CT scans that were independently annotated by three expert radiologists. The evaluation metrics focused on uncertainty and calibration, trying to encourage the community to acknowledge the need of these assessments to improve trust in the clinical world, and to exploit these multiple-rater annotations to address ambiguity in the data.
Seven international teams participated, submitting ten algorithms based on U-Net architectures, each with different strategies for handling variability, data scarcity, and inference efficiency. The evaluation went beyond traditional accuracy metrics such as the Dice Similarity Coefficient (DSC) to incorporate calibration quality, uncertainty estimation and volume as biomarker, in an attempt to go one step closer to the clinical world.
The exciting results showed that while all top models achieved high segmentation accuracy, the most robust solutions were those able to integrate multi-expert variability and provide well-calibrated uncertainty estimates. This is particularly relevant for complex structures such as the pancreas, where radiologists themselves often disagree.
🔑 Key points:
- The CURVAS challenge examined how AI handles segmentation in cases where experts do not always agree.
- Including expert variability in the evaluation enabled the models to be assessed in a more realistic and reliable way.
- Well-calibrated models not only segmented accurately, but also provided confidence scores that reflected their performance.
- Measuring organ volumes and dealing with ambiguous cases demonstrated the potential of these models to support real clinical use.
The CURVAS challenge shows that there is no single gold standard for segmentation. Rather, building trustworthy AI necessitates acknowledging expert disagreement, incorporating diverse datasets and evaluating models based on multiple criteria.
This work is an important step towards creating AI systems that are clinically meaningful and reliable.
👉 Read the full publication here: https://doi.org/10.1016/j.compbiomed.2025.111024